Hope4Sec is a collaborative R&D group of consultants and engineers in the field of mathematical and algorithmic engineering. Made up of three Estonians, one German and two French people, this group is supported by a European company for all matters relating to logistics and administrative and tax issues.
This collective has two flagship projects (among other ongoing R&D). The first concerns homomorphic data processing and analysis technologies. The disadvantage of cloud solutions is that the processing of data transferred to the cloud can only be carried out if the data is not encrypted, which makes it possible for an unauthorised third party to access the data. Hope4Sec already has significant results on clustering algorithms.
The second project concerns database-less and multi-layer information technologies. The challenge was to perform certain security functions (identity control, anti-fraud, etc.) in offline mode, without depending on a database, while being able to access a large amount of information with different levels of sensitivity. The mathematical validation is complete and we have several effective PoCs.
Interview with Hope4Sec, a European technology group. Interview by Philippe Richard.
Contact : contact@hope4sec.eu
Can you give examples of technologies you have developed or are developing?
We currently have two flagship projects (among other ongoing R&D):
- Homomorphic data processing and analysis technologies. The disadvantage of cloud solutions is that the processing of data transferred to the cloud can only be carried out if the data is unencrypted, making it possible for an unauthorised third party to access the data. The objective of the technology we are working on is to enable data analysis (ML, big data) to be carried out directly on the encrypted versions of the data, significantly reducing the computing time and the size of the data (and therefore the energy footprint) while guaranteeing that the results are identical to those that would be obtained on the unencrypted data. We already have significant results on clustering algorithms (millions of individuals with tens of thousands of characteristics) and the transition to supervised techniques is only a matter of time. But it is still a bit early to talk about it. We prefer to finalise the PoCs in progress.
- Database-less and multi-information-layer technologies. The challenge was to perform certain security functions (identity control, anti-fraud, etc.) in offline mode, without depending on a database, while being able to access a large amount of information with different levels of sensitivity. In many contexts and cases, the existence of such databases represents either a weakness or a danger. Indeed, we observe that a database has three essential « vocations »: to grow indefinitely, to be shared (and thus lead to misuse) and, worse, to be leaked. If we remove the database, we remove all these risks and simplify the management of the use-cases. The mathematical validation is complete and we have several effective PoCs. We are now working on the various and very numerous industrial applications and business variations.
Can you present an application of database-less technology?
The fundamental principle is based on the concept of multi-level data protection. From the same data (plaintext or encrypted text), we are able to store/extract other data (plain or encrypted) of the same size. This can be done with the same pair of keys for a whole population or class of objects. But it is possible to vary the number, characteristics of the keys and their management, depending on the application.
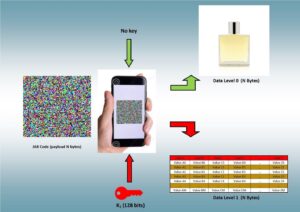
Let us take as a use-case – among many others – the fight against fraud or the management of stocks. Each product is provided with a JAB Code (https://jabcode.org/; it works in the same way as a QR-Code, but JAB codes can manage a greater quantity of data) containing a unique content (plain or encrypted). Scanning the code allows, depending on the key provided, access to two (or more) levels of data, possibly with different sensitivities (see Figures). If the content is clear, the K0 key is not useful. It is public information that anyone can access. On a part or a product (for example, a bottle of perfume), it can be the detailed description of the product. On the other hand, the K1 key, from the same information contained in the JAB Code, gives access to a different content of the same size but more sensitive and accessible only to those who have this key (a customs controller for example). The K1 key can be unique for all products, for each product class etc. There is no need to have a database to consult, it is possible to work without being connected…. However, this scenario can be extended by multiple variants, possibly with additional, but fully encrypted, databases that can only be consulted product by product (no global processing possible). It is worth stressing on the fact that the key size (128, 192, 256 bits) is far smaller that the size of data (N).
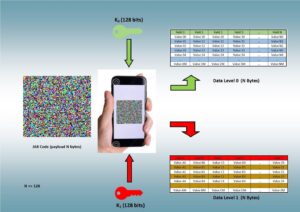
We can thus, with one unique JAB code, manage several hundred to several thousand different characteristics (depending on the application) and data for each product, with two, three, four… levels of security (to manage several classes of controllers or operators, for example).
Our technology allows an almost infinite number of applications. We have imagined, for example, another application concerning identity control, without a database (and therefore without possible misuse). The JAB code can be on the identity card, on a number plate, etc. The K0 key allows for a classic control, while the K1, K2, etc. keys give access to information of different security levels, accessible only to law enforcement agencies or competent authorities. This allows a balance between the citizen (who carries all the data concerning him or her but only accesses some of it) and the State (police, judge, authority), which must scan the code to access the most sensitive information. Thus, without a database, no leakage is possible, no security misuse is possible.
Other applications include dynamic code protection (against reverse engineering), multi-channel communication, digital watermarking, etc.
Do you think this type of technology has a future? Isn’t it a bit utopian?
It may still be the case, but mentalities are changing and technology is there to provide virtuous/smart solutions to problems. In fact, we are convinced that no one has ever imagined that we could see and solve these types of problems and applications in this way. Often a solution is not successful simply because the problem is poorly posed or not yet known. Technology must also help to show that a problem is badly formulated or that the perspective is wrong or even at odds with the most desirable human values. Our solutions provide a new approach and many answers/applications in the industrial field.