Tout le monde a déjà entendu parler du système d’exploitation Linux sans pour autant avoir pris la peine de faire le saut de Windows à celui-ci. De nombreux arguments existent appuyant les avantages d’un système Linux sur Windows, comme par exemple le libre-partage de connaissances, la gratuité de la majorité des distributions et des logiciels, et une communauté d’utilisateurs très active.
Néanmoins, il existe une légende urbaine : « il n’existe pas de vulnérabilités ni de malwares sur un système Linux ». Cette phrase est souvent présentée comme un avantage majeur des systèmes Linux en mettant en avant le fait que Windows soit le système d’exploitation le plus répandu au monde, ce qui implique que le nombre de cibles potentielles est bien plus élevé. Elle est cependant totalement fausse ! Voici une étude de la stabilité et de la sécurité des applications Linux par fuzzing.
par Clément SICCARDI et Raphaël PION
Laboratoire (C+V)O , Axe Confiance Numérique et Sécurité/Laboratoire de cryptologie et virologie opérationnelles (ESIEA)
![]()
Pas de virus sous Linux ! Cette affirmation est fausse. Elle ignore la prévalence de Linux dans tous les systèmes n’étant pas des ordinateurs personnels (en particulier tous les types de serveurs). De plus, que ce soit pour Windows ou pour Linux, les logiciels sont programmés par des humains faisant naturellement des erreurs, impliquant des vulnérabilités et des failles de sécurité dans ceux-ci.
Définition du plantage d’une application :
Lorsqu’un programme s’arrête brutalement et ne répond plus, nous pouvons être confrontés à une véritable exploitation d’une vulnérabilité pouvant exécuter du code malveillant. Pour tester un programme, nous avons donc la possibilité de forcer un arrêt brusque et inexpliqué de l’application en question et analyser la nature du crash produit. Lors de son exécution, une application a besoin de mémoire vive. Cette mémoire étant allouée par le système d’exploitation, si une application tente d’accéder à une zone mémoire qui ne lui est pas allouée, le système d’exploitation va stopper son exécution. Pour ce faire, il va envoyer un signal de retour, un SIGSEGV, et l’application se fermera. On parle alors d’un buffer-overflow[1]. Il ne reste plus qu’à en analyser la cause.
Pour faire simple, un dépassement de mémoire arrive quand une quantité de données est stockée dans une région de la mémoire trop petite pour la contenir.
De façon imagée, on peut voir cela comme un seau se remplissant d’eau (l’espace alloué pour les données stockant une chaîne de caractère par exemple). Bien entendu, lorsque l’on remplit trop ce seau, il déborde : c’est le dépassement de mémoire. Au débordement, l’eau (les données) se répand sur le sol, qui représente la mémoire non allouée. Un attaquant peut très bien arriver à contrôler la façon dont le surplus de données est réécrit afin d’exécuter du code malicieux.
La problématique est donc maintenant de réussir à forcer le plantage de l’application et à automatiser l’analyse ainsi que la relance des tests. Cette technique d’automatisation porte un nom : le fuzzing.
Définition du fuzzing :
Par définition, le fuzzing [2] est une méthode ayant pour but de tester un programme en lui injectant en entrée des données aléatoires ou volontairement malformées.
Cette technique a fait ses premiers pas en 1989. Le professeur Barton Miller de l’Université du Wisconsin a pour la première fois utilisé une technique qu’il nommera fuzzing afin de tester la robustesse des applications UNIX. Le fuzzing est très fortement lié à la Boundary-value analysis, qui est une analyse de programme testant la limite des valeurs utilisées dans celui-ci. La BVA permet de mettre en place des filtres afin de gérer les exceptions et les erreurs dans une application.
Le fuzzing peut se comparer à une intrusion dans une maison. Si nous avons la totalité du code source du programme analyser, c’est comme si nous avions les plans de cette maison. L’étude sera donc plus facile et plus rapide, on parle alors de White-box testing.
L’analyse peut se faire sans code source (appelé Black-box texting), dans ce cas, l’analyse d’un crash sera beaucoup plus difficile. On peut comparer cela à un cambriolage de nuit, sans luminosité et sans plan. Il faudra désassembler le programme, bloc par bloc afin de trouver la raison de cet arrêt brutal. On parle de reverse-engineering.
Il est aussi possible de n’avoir seulement accès qu’à une partie du code source. On parle de Grey Box testing.
Le fuzzing permet donc de tester tous les systèmes possibles. On peut très bien fuzzer un système électronique comme on fuzzerait un programme informatique. Par exemple, les lecteurs de carte NFC (Near-Field Communication), présents dans les cartes bancaires par exemple, pourraient être testés en envoyant des données malformées sur des cartes possédant ce dispositif. Le fuzzing peut s’appliquer à un réseau, en envoyant des données aléatoires sur les ports d’une machine, ou encore à une page web, en essayant de répondre à un formulaire avec des données aléatoires.
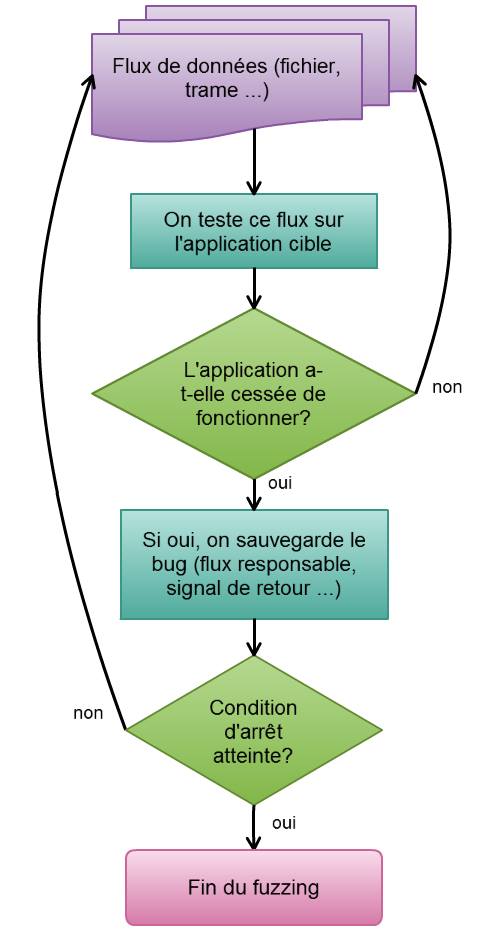
Figure 1 – Schéma fonctionnel de la méthode de fuzzing
Nous allons parler ici de l’étude des applications dans un système d’exploitation. Le fuzzing permet de tester efficacement les applications afin de les rendre plus sûres.
On se rend vite compte qu’envoyer des caractères aléatoires à un programme comme une visionneuse d’image ne va pas nous mener bien loin. C’est pour cela qu’il existe divers outils nommés « fuzzers » (fuzzeurs) permettant d’appliquer un fuzzing intelligent : modifier de manière aléatoire les données sensibles d’un fichier comme son header ou simplement son contenu brut. À partir de là, il n’y a qu’à simplement envoyer ce fichier (qui peut être corrompu ou toujours lisible) à l’application, et à regarder si elle a été codée pour gérer toutes les erreurs présentes dans le fichier.
Le Format File fuzzing
Des programmes existent permettant de fuzzer spécifiquement un format de fichier : cela s’appelle le « file format fuzzing ». Un exemple simple est le format image BMP. Un fichier BMP comporte un header d’une taille fixe, et ensuite le code RVB de chacun des pixels de l’image. Le fuzzing le plus élémentaire d’une image BMP serait de supprimer le header et regarder si l’application gère cette erreur. Un autre type de modification serait de tronquer les derniers octets de l’image et encore une fois l’envoyer à la visionneuse d’image. Les applications fuzzant des fichiers BMP testent ces modifications ainsi que de multiples autres et automatisent intelligemment le processus, tout en enregistrant chaque plantage de l’application avec des informations capitales pour l’analyse de vulnérabilités (signal de retour, fichier qui a fait crasher l’application ainsi que son fichier original).
Le file format fuzzing, modifiant directement le contenu d’un fichier, présentera des résultats d’autant plus fructueux que le fichier de base est complexe. Par exemple, on entend bien souvent parler de vulnérabilités découvertes dans tel ou tel lecteur de fichiers PDF, cela est dû au fait que le format PDF est un véritable couteau suisse et que l’on peut mettre énormément de choses à l’intérieur d’un tel fichier : images, vidéos, code exécutable Javascript
Il faut donc que le lecteur soit programmé pour être résistant à toutes les vulnérabilités possibles sur toutes ses composantes éventuelles. Autre exemple, le format vidéo MKV, qui est en réalité un conteneur permettant d’assembler plusieurs sources vidéo et audio utilisant différents codecs (DivX, x264
pour la vidéo ; AAC, MP3
pour l’audio), ainsi que plusieurs pistes de sous-titres dans un même fichier, peut être facilement et profitablement fuzzé, car son architecture est complexe et son contenu riche.
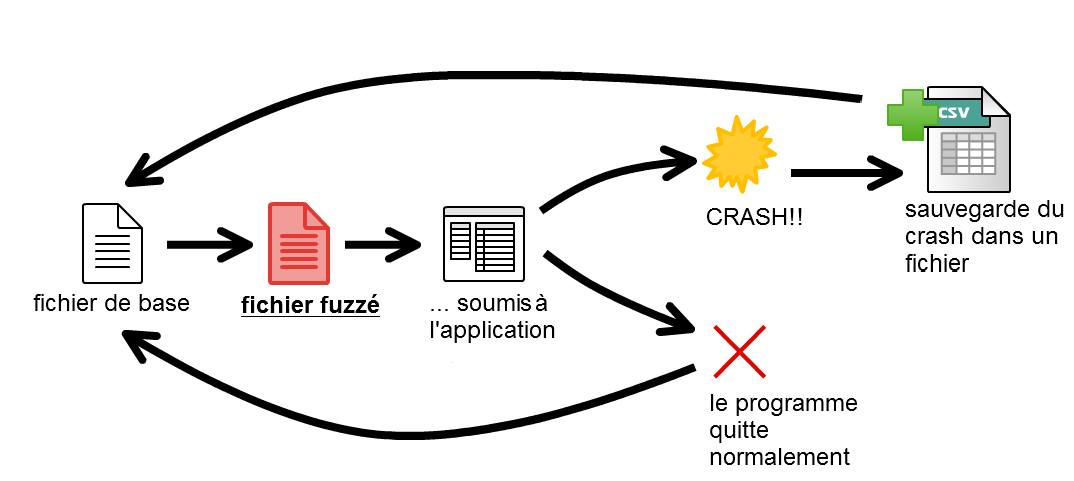
Figure 2 – Déroulement du file format fuzzing
Le fuzzing est donc une méthode de test de programme assez complète qui présente énormément de résultats. Malgré cela, elle reste encore assez peu utilisée dans le monde de la programmation simplement car elle n’est pas très connue, ou alors parce que pour beaucoup encore la sécurité n’est pas la priorité et ce sera bien souvent la partie du projet qui sera oubliée et reportée en cas de contrainte temporelle ou financière. Cependant ce doit être une étape clé de l’assurance qualité du projet car extrêmement simple à mettre en place et pouvant produire des résultats étonnants.
Cette méthode présente toutefois des inconvénients. Premièrement ce n’est en aucun cas une analyse exhaustive des vulnérabilités du logiciel. Deuxièmement le fuzzing demande énormément de ressources à un ordinateur. Bien souvent, un poste devra entièrement être alloué au test, et des optimisations peuvent être effectuées sur le script de test, comme la gestion du multi-threading au niveau du processeur. On pourrait aussi installer des clusters (ordinateurs travaillant ensemble en série) afin d’améliorer la rapidité du fuzzing.
Bibliographie :
[1] http://insecure.org/stf/smashstack.html (Aleph One, 1996)
[2] « Fuzzing brute force vulnerability discovery » (H. D. MOORE, 2007)
[3] zzuf, outil de fuzzing, http://caca.zoy.org